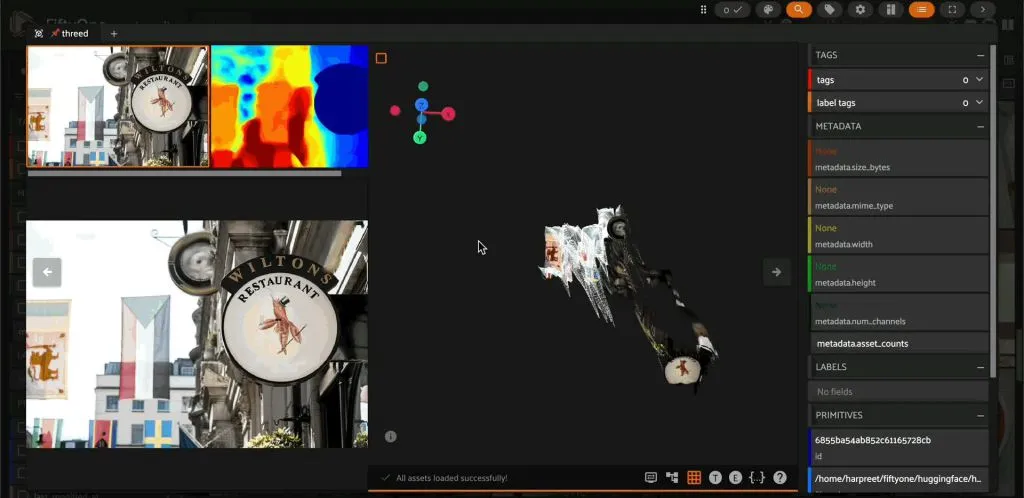
A joint research effort from Peking University, the Chinese University of Hong Kong (CUHK), and Shanghai AI Lab unveiled VGGT-Edit, a 3D scene editing framework capable of rendering results at an unprecedented speed of 120 times faster than previous state-of-the-art methods.
This breakthrough significantly advances the field of generative 3D content creation by providing a highly efficient mechanism for modifying complex three-dimensional environments in real time. The system allows researchers and developers to perform intricate edits on existing scenes, effectively manipulating objects, textures, and scene geometry with high fidelity while maintaining computational tractability.
The development addresses a critical bottleneck in current 3D generative models: the trade-off between visual quality and inference speed. Traditional methods often require extensive computational resources or iterative refinement processes, making real-time interactive editing impractical for widespread application across industries such as virtual reality (VR), augmented reality (AR), and digital media production.
VGGT-Edit leverages sophisticated architectural innovations to achieve its performance gains. The framework integrates advanced neural rendering techniques with optimized scene representation methods, enabling rapid convergence during the editing process. This efficiency is crucial for applications requiring immediate visual feedback from user interaction within a 3D space.
Technical Architecture and Performance Gains
The core contribution of the VGGT-Edit framework lies in its ability to decouple high-resolution synthesis from computationally intensive optimization loops. Researchers demonstrated that by restructuring how scene information is encoded and decoded, the model can predict edited outcomes much faster than contemporary pipelines.
Specifically, the research team focused on improving the efficiency of the underlying neural rendering pipeline responsible for synthesizing novel views after an edit has been proposed. This optimization allowed the framework to achieve a speedup factor exceeding 120x compared to prior benchmarks in the domain of 3D scene manipulation.
The collaboration between Peking University, CUHK, and Shanghai AI Lab brought together diverse expertise in deep learning, computer vision, and large-scale model deployment. This multidisciplinary approach was instrumental in tackling the complex interplay between semantic editing requirements and photorealistic rendering demands inherent in 3D scene modification.
The framework supports various types of edits, ranging from localized object replacements to global environmental alterations. The precision of these edits suggests a deep understanding of geometric consistency and material properties within the generated scenes, moving beyond superficial texture swaps.
Implications for Digital Content Creation
The introduction of VGGT-Edit has substantial implications for industries relying on synthetic 3D environments. For film production, architects designing virtual walkthroughs, or game developers prototyping new levels, the ability to iterate complex scene changes instantly transforms the creative workflow.
Current workflows often mandate lengthy render queues for even minor adjustments; VGGT-Edit mitigates this latency, enabling a more fluid and intuitive design process. This speed enhancement democratizes high-quality 3D editing, making advanced capabilities accessible outside of highly specialized research labs.
Furthermore, the framework contributes directly to the maturation of real-time neural rendering technology. As generative AI moves from static image synthesis to dynamic, interactive scene construction, efficiency becomes as paramount as fidelity. VGGT-Edit sets a new high bar for this critical intersection of speed and quality in 3D computer graphics.


